Top news of the week: 15.07.2021.
Research


NVIDIA AI Essentials Learning Series
Kickstart your career in AI in this AI Learning Series.
The Bayesian Learning Rule
We show that many machine-learning algorithms are specific instances of a single algorithm called the Bayesian learning rule. The rule, derived from Bayesian principles, yields a wide-range ...
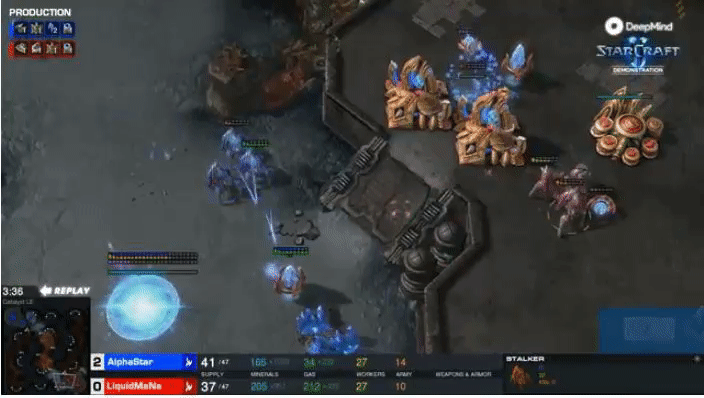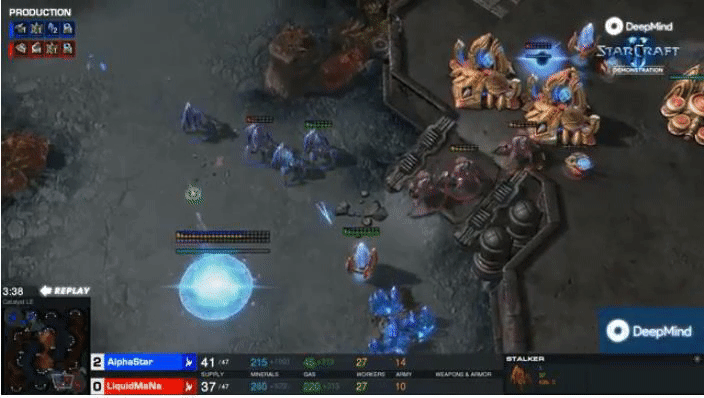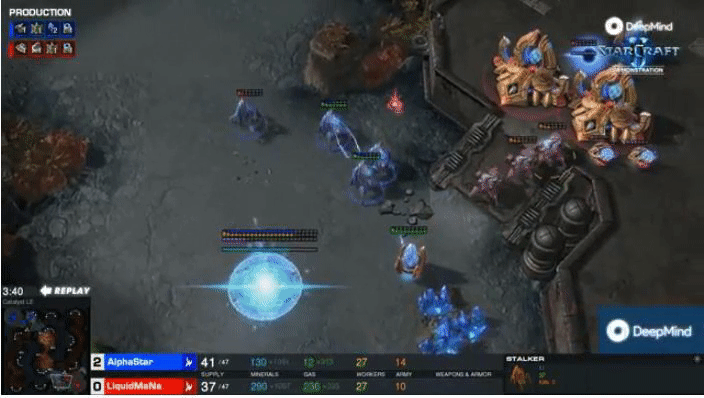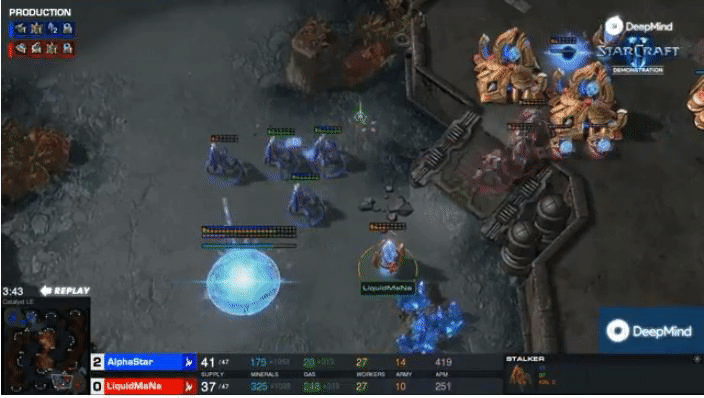
Gradient Matching for Domain Generalization
Machine learning systems typically assume that the distributions of training and test sets match closely. However, a critical requirement of such systems in the real world is their ability ...
Machine learning algorithms for automated decision making under domain shift
PhD Project - Machine learning algorithms for automated decision making under domain shift at University College London, listed on FindAPhD.com

Coding with GitHub Copilot
My thoughts and experience on the new GitHub Copilot tool.
Why Generalization in RL is Difficult: Epistemic POMDPs and Implicit Partial Observability
Generalization is a central challenge for the deployment of reinforcement learning (RL) systems in the real world. In this paper, we show that the sequential structure of the RL problem ...