Top news of the week: 10.08.2022.
MultiNeRF: A Code Release for Mip-NeRF 360, Ref-NeRF, and RawNeRF
A Code Release for Mip-NeRF 360, Ref-NeRF, and RawNeRF - GitHub - google-research/multinerf: A Code Release for Mip-NeRF 360, Ref-NeRF, and RawNeRF
Beyond neural scaling laws: beating power law scaling via data pruning
Widely observed neural scaling laws, in which error falls off as a power of the training set size, model size, or both, have driven substantial performance improvements in deep learning. ...

The Singular Value Decomposition
we can state this as an optimization problem: This problem simply asks for the input 𝐱 for which the resulting vector 𝐌𝐱 has maximal magnitude, subject to the constraint that …
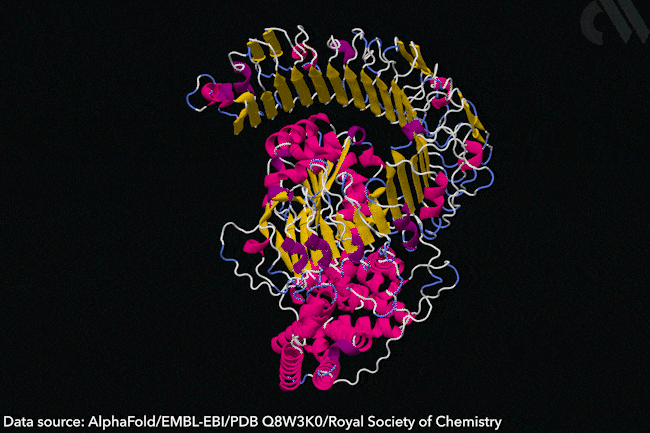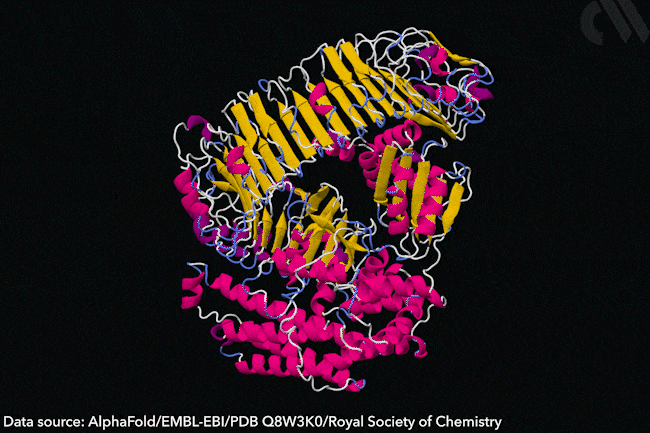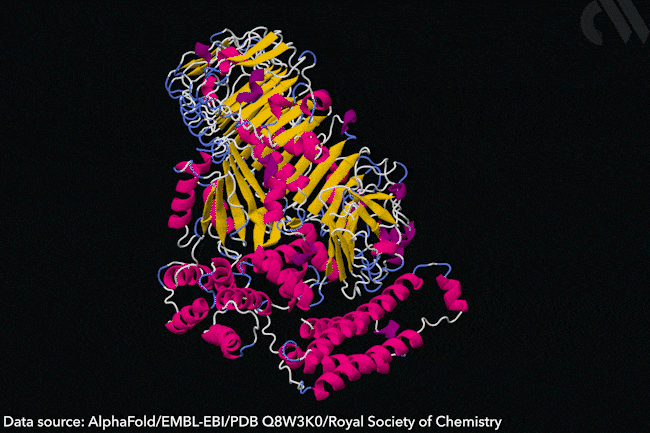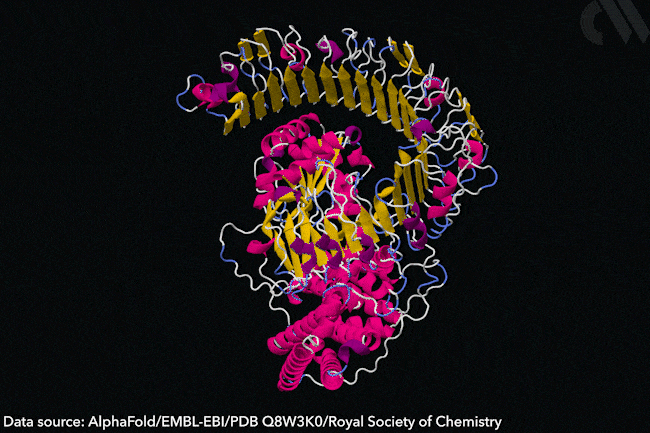
Why AlphaFold won’t revolutionise drug discovery
Protein structure prediction is a hard problem, but even harder ones remain

Aman Chadha’s Post
📚 Natural Language Processing from Stanford University: Distilled Notes 👉🏼 http://nlp.aman.ai - NLP is one of the most popular #AI domains, widely... 15 comments on LinkedIn
Multimodal Learning with Transformers: A Survey
Transformer is a promising neural network learner, and has achieved great success in various machine learning tasks. Thanks to the recent prevalence of multimodal applications and big data, ...

First Workshop on Interpolation Regularizers and Beyond
Interpolation regularizers are an increasingly popular approach to regularize deep models. For example, the mixup data augmentation method constructs synthetic examples by linearly ...

Subscribe to The Batch
In this issue of The Batch: Autonomous aircraft in the UK are getting their own superhighway | Worldwide collaboration produced the biggest open source language model