Calculus, Mathematics, Machine learning, Lexical category, Regression analysis, Linear algebra
Stochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
RT @wellecks: “Estimating Gradients for Discrete Random Variables by Sampling without Replacement“ https://t.co/rj0qKeod1N
Proposes the unordered set estimator & policy gradient
Can be used with stochastic beam search (https://t.co/40arztciix)
by @wouter_kool, Herke van Hoof, @wellingmax https://t.co/vqkIUqeHGq
Open(8) Now for each node S, we define GφS as the maximum of the perturbed log-probabilities Gφi in the subtree leaves S. By Equation (2), GφS has a Gumbel distribution with location φS (hence its notation GφS ): GφS = max i∈S Gφi ∼ Gumbel(φS) (9) Since GφS ∼ Gumbel(φS) is a Gumbel ...
RT @wellecks: “Estimating Gradients for Discrete Random Variables by Sampling without Replacement“ https://t.co/rj0qKeod1N
Proposes the unordered set estimator & policy gradient
Can be used with stochastic beam search (https://t.co/40arztciix)
by @wouter_kool, Herke van Hoof, @wellingmax https://t.co/vqkIUqeHGq
OpenStochastic Beams and Where to Find Them: The Gumbel-Top-k Trick for Sampling Sequences Without Replacement
(8) Now for each node S, we define GφS as the maximum of the perturbed log-probabilities Gφi in the subtree leaves S. By Equation (2), GφS has a Gumbel distribution with location φS (hence ...
We are sorry, we could not find the related article
If you are curious about Artificial Intelligence News Essentials and Research
Please click on:
Or signup to our newsletters
Click here to read the article
Training -ELBO (1020 latent space) 158.8 k=1 RELAX 94.4 k=1 ST Gumbel-Softmax 84.4 k=1 REINFORCE (sample bl) 82.6 k=4 Sum & sample (sample bl) 82.3 k= * ARSM 80.9 k=8 Sum & sample (sample ...
Learning Latent Trees with Stochastic Perturbations and Differentiable Dynamic Programming
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5508–5521 Florence, Italy, July 28 - August 2, 2019. c©2019 Association for Computational ...
tagging.dvi
Stanford University Stanford University Stanford, CA 94305-9040 Stanford, CA 94305-9040 [email protected] [email protected] Christopher D. Manning Yoram Singer Computer Science ...
Essential Math for Data Science: ‘Why’ and ‘How’
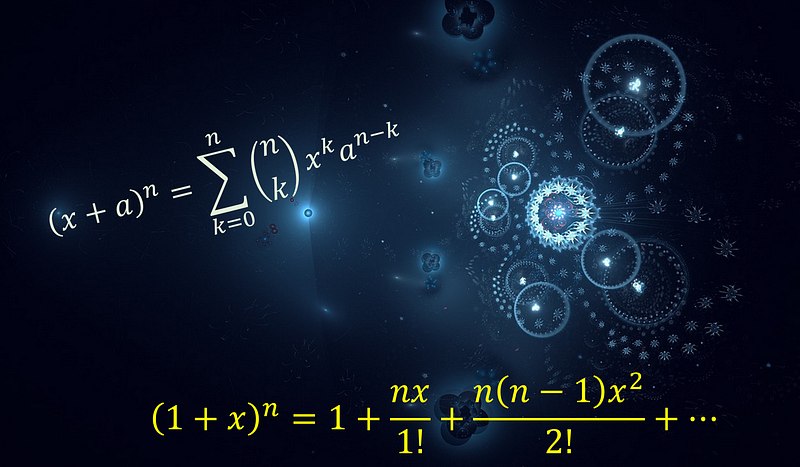
Data summaries and descriptive statistics, central tendency, variance, covariance, correlation, Basic probability: basic idea, expectation, probability calculus, Bayes theorem, conditional ...
Essential Math for Data Science — ‘Why’ and ‘How’
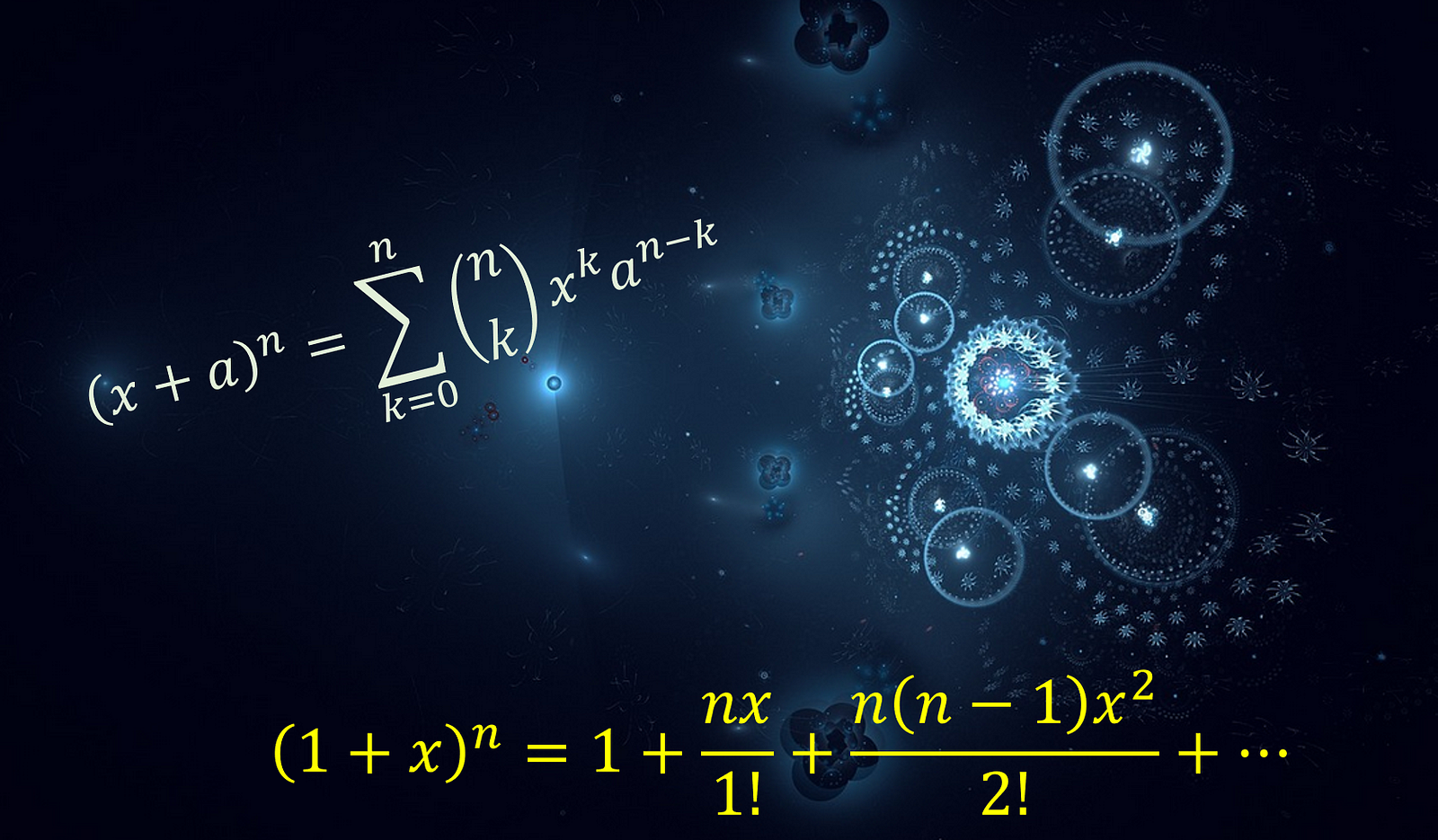
Mathematics is the bedrock of science. We discuss the essential math topics to master to become a better data scientist in all aspects.