Das Model, Model, Graphics processing unit, Language model, Parallel computing, Training
Mosaic LLMs (Part 2): GPT-3 quality for <$500k
Training large language models (LLMs) costs less than you think. Using MosaicML Cloud, we show how fast, cheap, and easy it is to train these models at scale (1B -> 70B parameters). ...

Mosaic LLMs (Part 2): GPT-3 quality for <$500k
Training large language models (LLMs) costs less than you think. Using MosaicML Cloud, we show how fast, cheap, and easy it is to train these models at scale (1B -> 70B parameters). ...
We are sorry, we could not find the related article
If you are curious about Artificial Intelligence and Research
Please click on:
Subscribe to Artificial Intelligence - Research

OpenAI is reducing the price of the GPT-3 API — here’s why it matters
OpenAI has a new pricing plan, effective Sept. 1, that will impact companies using its flagship large language model (LLM), GPT-3.

Train a TensorFlow Model with a Kubeflow Jupyter Notebook Server
This series aims to demonstrate how Kubeflow helps organizations with machine learning operations (MLOps).
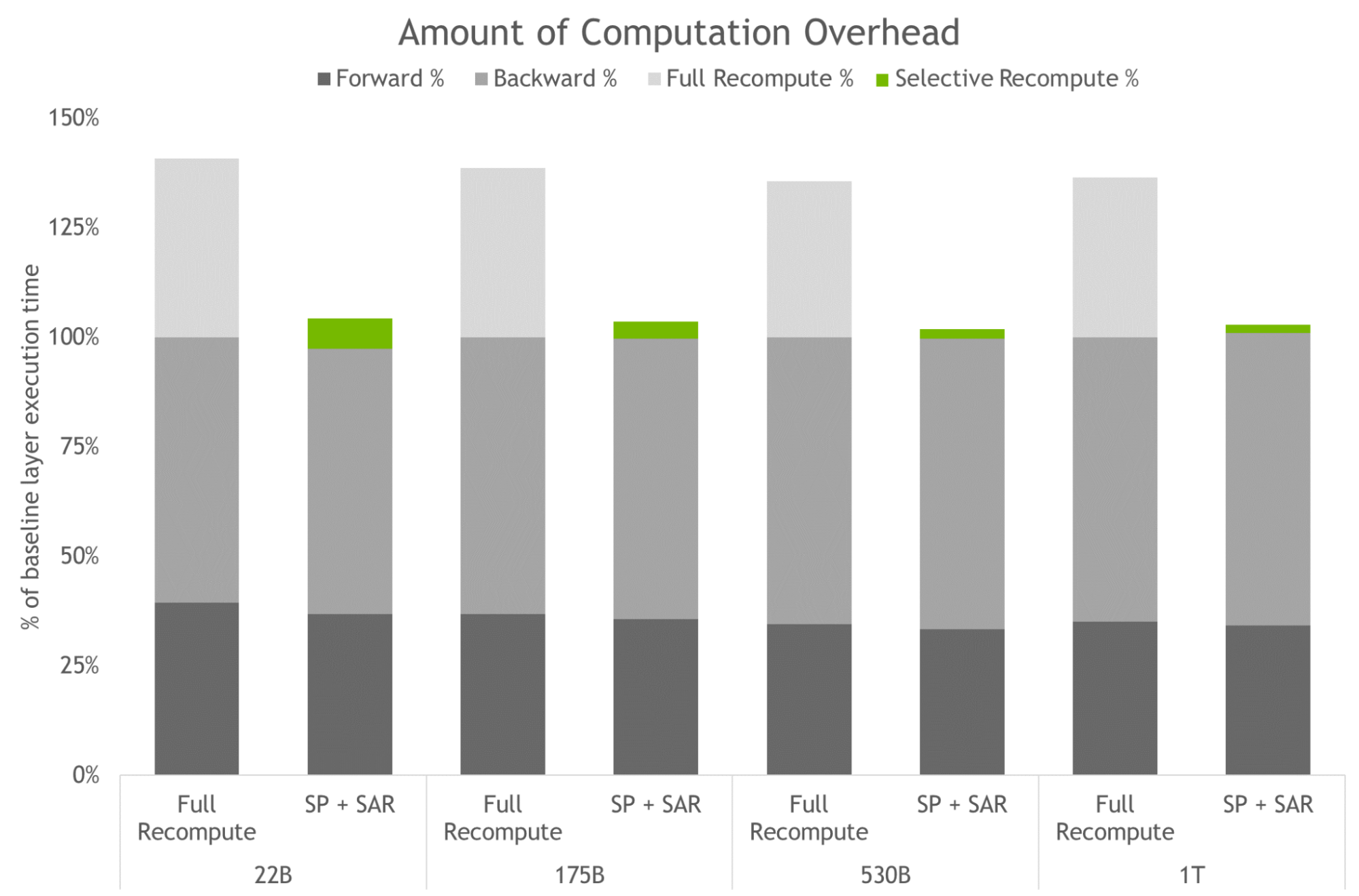
NVIDIA AI Platform Delivers Big Gains for Large Language Models
NVIDIA AI platform makes LLMs accessible. Announcing new parallelism techniques and a hyperparameter tool to speed-up training by 30% on any number of GPUs.
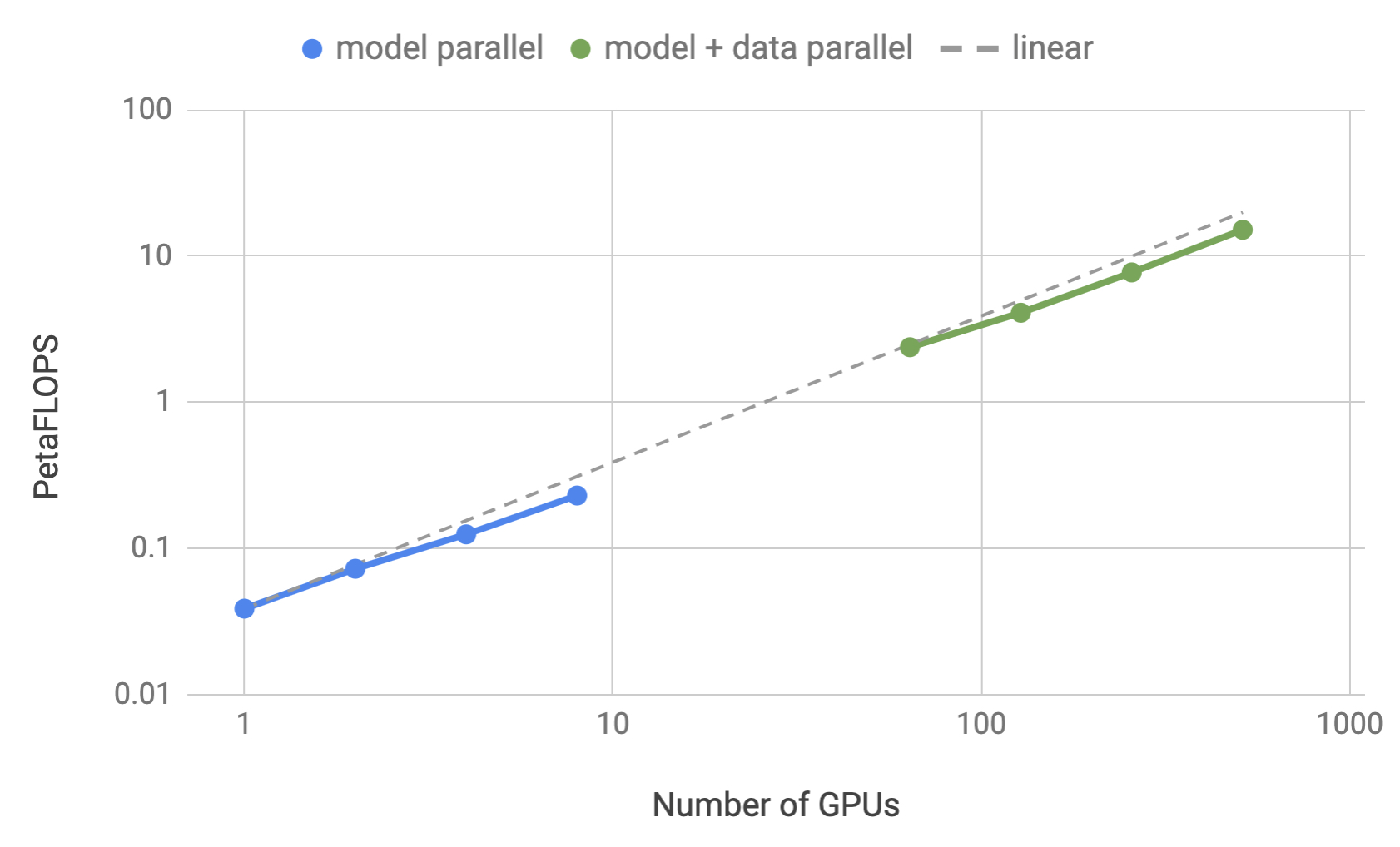
MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism
We train an 8.3 billion parameter transformer language model with 8-way model parallelism and 64-way data parallelism on 512 GPUs, making it the largest transformer based language model ...
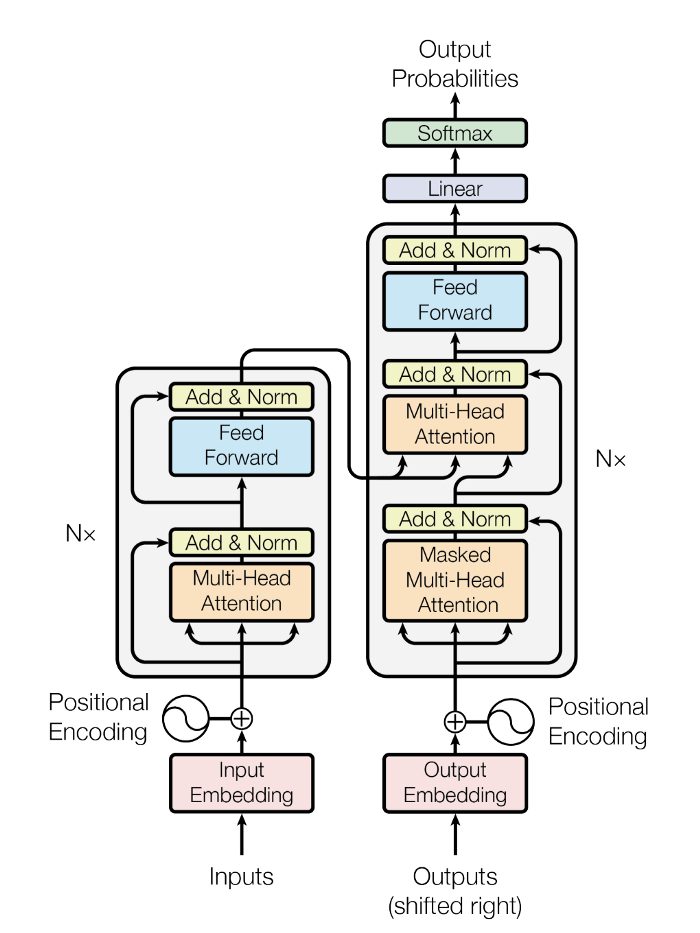
Transformer models: an introduction and catalog — 2022 Edition
Params: 5B, 2.7B (XL) Corpus: Pile — 840 GB open source text dataset that combines 22 pre existing datasets Lab: EleutherAI Imagen Family: T5, CLIP, Diffusion models Pretraining ...
Introducing the Model Garden for TensorFlow 2
MirroredStrategy - for multiple GPUs (If no GPUs are found, CPU is used) MultiWorkerMirroredStrategy - for multiple hosts each with multiple GPUs TPUStrategy - for multiple TPUs or multiple ...

Introducing PyTorch Lightning Sharded: Train SOTA Models, With Half The Memory
Lightning 1.1 reveals Sharded Training — train deep learning models on multiple GPUs saving over 50% on memory, with no performance loss…
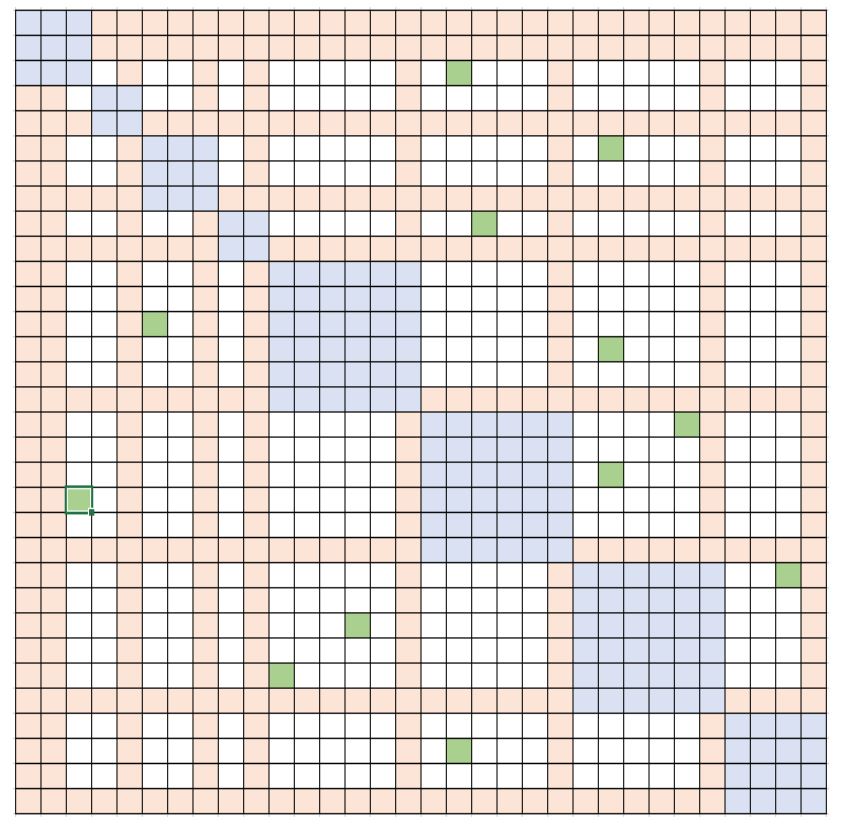
DeepSpeed: Extreme-scale model training for everyone
DeepSpeed continues to innovate, making its tools more powerful while broadening its reach. Learn how it now powers 10x bigger model training on one GPU, 10x longer input sequences, 5x less ...

Energy and Policy Considerations in Deep Learning for NLP
🔬 Research summary by Abhishek Gupta (@atg_abhishek), our Founder, Director, and Principal Researcher. [ Original paper by Emma Strubell, Ananya Ganesh, and Andrew McCallum] Overview: As ...

Ludwig on PyTorch
How we ported Ludwig to PyTorch, the declarative deep learning framework, and how the PyTorch community can benefit from it

gpt-2-simple
Python package to easily retrain OpenAI's GPT-2 text-generating model on new texts - minimaxir/gpt-2-simple

Incubator Insights #007
In this issue we discuss interesting developments in applied AI, including search technology with Vespa.ai, few-shot entity extraction, and open-source large models.

Training TensorFlow Object Detection Models
Take a look at training tensorFlow object detection models as well as explore a quick overview of the main steps that you can follow to train the models.

AI caramba, those neural networks are power-hungry: Counting the environmental cost of artificial intelligence
(And, also worryingly, its increasing financial cost)

Delivering AI model training to the enterprise with HPE and NVIDIA
Will you be joining Supercomputing 2021 happening November 14-19? In anticipation of the event, HPE's Evan Sparks and NVIDIA’s Jim Scott got together to discuss the powerful new solution ...
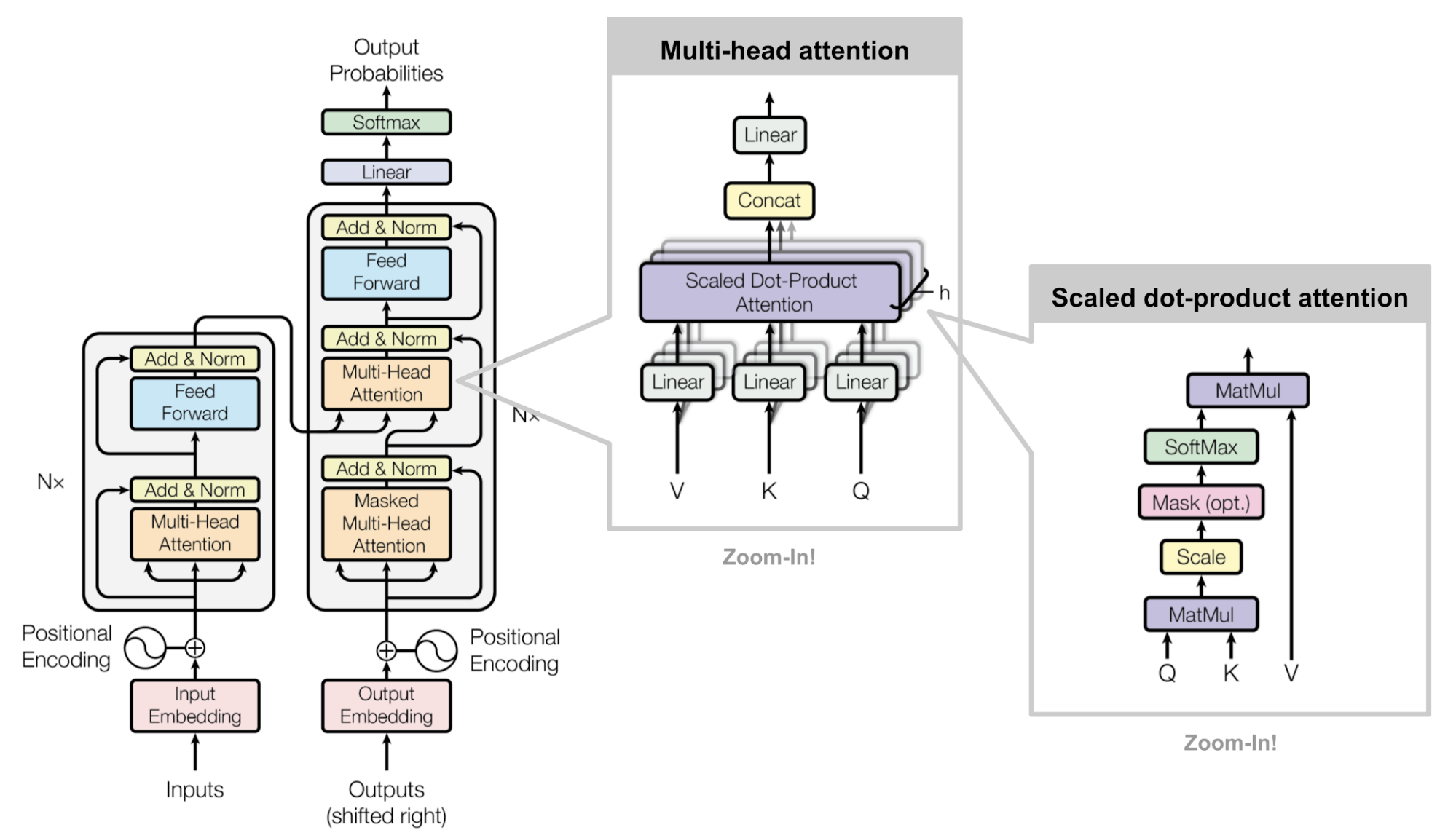
The Transformer Family
Inspired by recent progress on various enhanced versions of Transformer models, this post presents how the vanilla Transformer can be improved for longer-term attention span, less memory ...

Cerebras Slays GPUs, Breaks Record for Largest AI Models Trained on a Single Device
Democratizing large AI Models without HPC scaling requirements.

AI Infrastructure for Everyone, Now Open Source
Lack of software infrastructure is a fundamental bottleneck in achieving AI’s immense potential – a fact not lost on tech giants like Google, Facebook, and Microsoft. These elite firms have ...