Environmentalism, Natural environment, Learning, Reinforcement learning, Machine learning, Algorithm
Enhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions
RT @kenneth0stanley: In case you didn’t have time for our arxiv paper on Enhanced POET, a quicker blog post with videos and pictures was just released. See enhancements like domain-general environmental diversity metrics and a new open-ended progress measure: https://t.co/F4i1AajVf2 1/ https://t.co/n1yAREXvUb
OpenBuilding upon our existing open-ended learning research, Uber AI released Enhanced POET, a project that incorporates an improved algorithm and allows for more diverse training environments.
RT @kenneth0stanley: In case you didn’t have time for our arxiv paper on Enhanced POET, a quicker blog post with videos and pictures was just released. See enhancements like domain-general environmental diversity metrics and a new open-ended progress measure: https://t.co/F4i1AajVf2 1/ https://t.co/n1yAREXvUb
OpenEnhanced POET: Open-Ended Reinforcement Learning through Unbounded Invention of Learning Challenges and their Solutions

Building upon our existing open-ended learning research, Uber AI released Enhanced POET, a project that incorporates an improved algorithm and allows for more diverse training environments.
We are sorry, we could not find the related article
If you are curious about Artificial Intelligence News Essentials and Research
Please click on:
Or signup to our newsletters
POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and their Solutions through the Paired Open-Ended Trailblazer
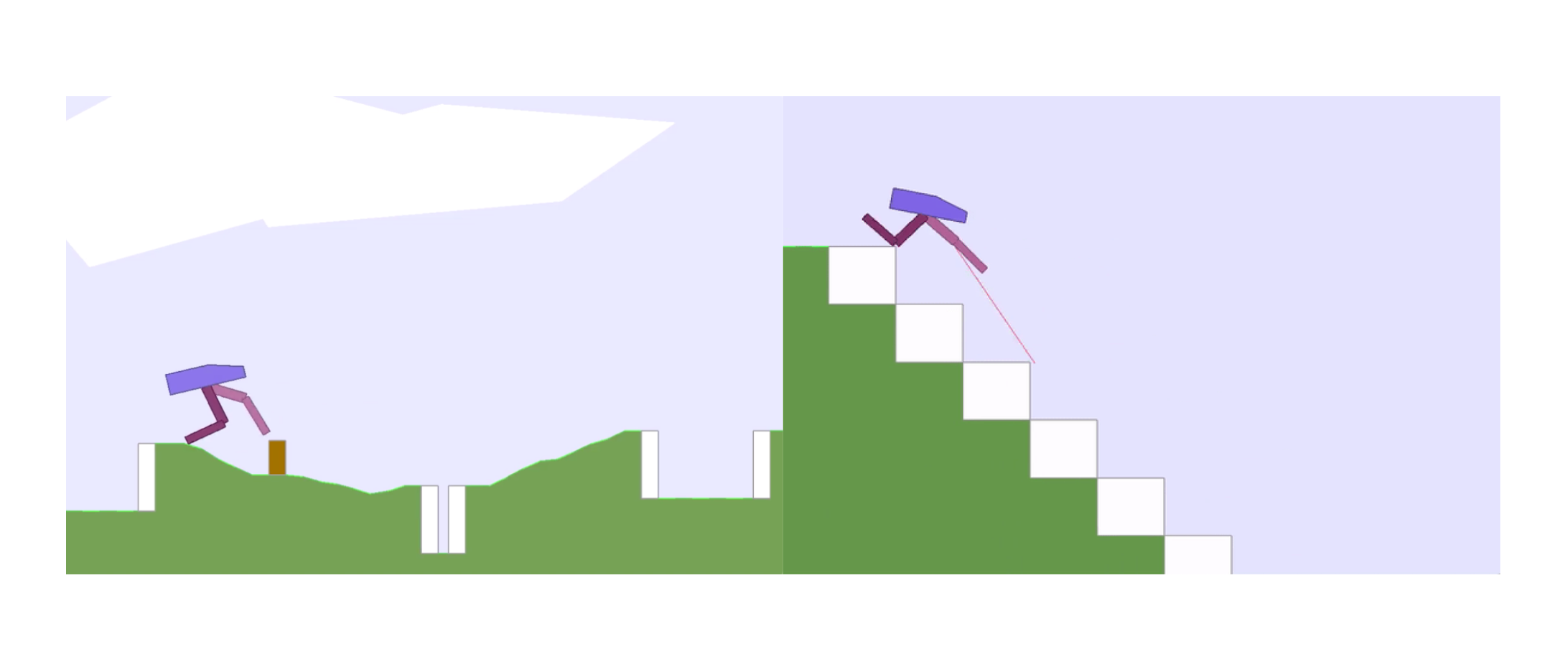
Uber AI Labs introduces the Paired Open-Ended Trailblazer (POET), an algorithm that leverages open-endedness to push the bounds of machine learning.
Click here to read the article
Furthermore, the environments are easily modified, enabling numerous diverse obstacle courses to emerge to showcase 7 Algorithm 2 POET Main Loop 1: Input: initial environment Einit(·), its ...
Introduction: Reinforcement Learning with OpenAI Gym

Understand all the basic concepts and test your algorithms in OpenAI gym. So, get started with a quick demo for hands on experience.
Neuroevolution of Self-Interpretable Agents
Evolved to focus on a fraction of its vision critical for survival.
Google’s ML-fairness-gym lets researchers study the long-term effects of AI’s decisions
Google's ML-fairness-gym, which was released in open source, allows AI practitioners and data scientists to study the fairness of AI systems.

![[P] PyTorch version of NEAT (UberAI Lab)](https://external-preview.redd.it/C2_Zg5bFn1bTgWbShNf3DdbBBTv06AmI1ioCO_ADq8s.jpg?auto=webp&s=818add26d81640465323f9ee6e746ae67121827e)
21 Must-Know Open Source Tools for Machine Learning you Probably Aren’t Using (but should!)

Here are 21 incredible open source tools for machine learning every data scientist should know. Computer vision, NLP, ML - check out these tools.
MetaGenRL: Improving Generalization in Meta Reinforcement Learning

Biological evolution has distilled the experiences of many learners into the general learning algorithms of humans. Inspired by this process, MetaGenRL distills the experiences of many ...
Reinforcement learning helped robots solve Rubik’s Cube—does it matter?

OpenAI created a robotic hand that solves the Rubik's Cube. It's an interesting feat, but not a breakthrough in artificial intelligence.
arl00301 352..365
D. Ha Reinforcement Learning for Improving Agent Design Artificial Life Volume 25, Number 4 353 works further investigated morphology evolution [4, 8, 9, 11, 37, 44, 64, 65, 70], modular ...
Intrinsically Motivated Discovery of Diverse Patterns in Self-Organizing Systems

Developmental Systems, a Blog of the Flowers Lab
Quantifying Generalization in Reinforcement Learning

We’re releasing a new training environment, CoinRun, which provides a metric for an agent's ability to transfer its experience to novel situations, and has already helped clarify a ...
Reinforcement Learning for Improving Agent Design
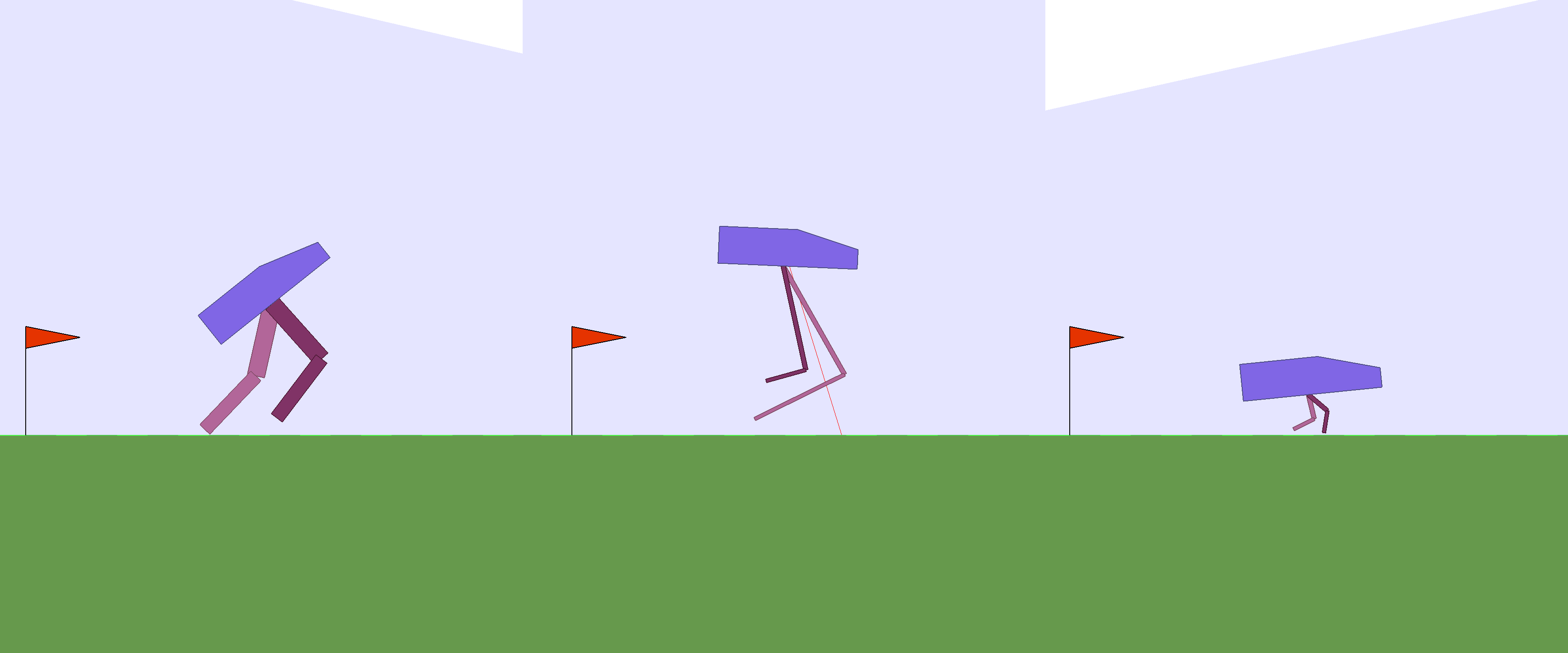
What happens when we let an agent learn a better body design?
Discovery of independently controllable features through autonomous goal setting

An intrinsically motivated agent How is it possible to discover what can be controlled from images ? This blog post is accompanied with a colab notebook Despite recent ...